What I don’t like about chains of thoughts and why language is a bottleneck to efficient reasoning.
20 may, 2023
Chain of thought (COT) is a formidable yet simple idea that empowers autoregressive LLM (gpt-like) models by allowing them to “reason” by explaning (in language) step by step how to solve a give problem. It has unlocked a lot of use cases that LLM (even instruct one) could not solve initially. It might have actually surprise AI researchers by how well it is working and has become a essential tool for AI practitioners.
As an engineer I do believe that COT will play a major role in converting current LLM capability into real world usage (and into money as well). Nevertheless I will in this blog post let my scientific self speak and explain why I believe that COT and the agent wave is mainly a hack of LLM to make them express reasoning in a inefficient way.
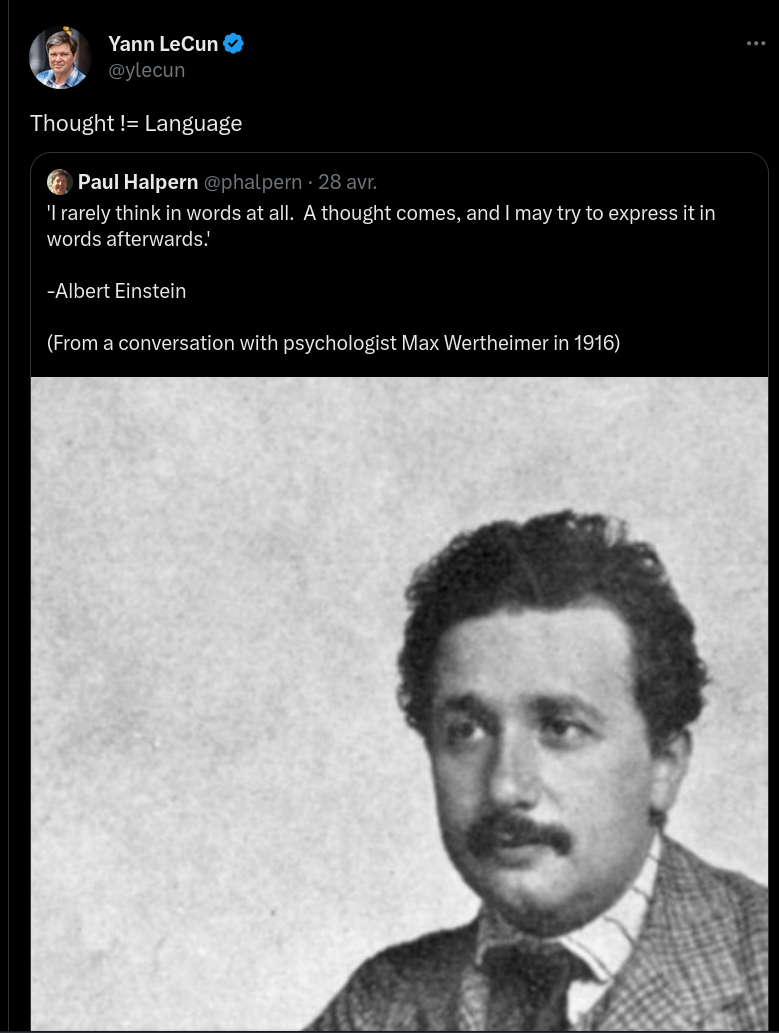
I thought that LLM can’t reason
It all started in the Jina AI office in Berlin in a heated after work AI debate with two colleagues of mine. The discussion quickly turned (as always in this office) into a debate around the capacity of current LLM and how far are we from human-like inteligence.
Even though I am amazed, like everybody, of the capacity of the GPT-like model I am in the camp of “We are still very far away from human intelligence let alone what people fantasize as AGI”.
At some point one of my colleagues started explaining that with the help of tool like Chain of Though and agents, current LLMs expose human-like cognitive ability like reasoning, reflection , ability to correct itself … and I had to step up and use my (what I thought was) deadly argument to show that LLM are still dumb in some way.
Did you know that it requires the same amount of compute for a LLM to perform the two following task ?
- Pick the first 10 numbers greater than 100 000
- Pick the first 10 prime numbers greater than 100 000
PS: why greater than 100 000 ? Otherwise if I had asked for the 10 first prime numbers the model would have most likely remembered all of them already.
Indeed LLM created a sentence by doing next token prediction, i.e. they predict the next token by computing forward pass over the entire (gigantic) network and compute attention between the different tokens (in a causal way each token look only at token from the past) and picking the most likely token according to its training statistical distribution.
This means that if the length of your output fits in 30 tokens then the time of inference will be exactly 30 times the time needed to do one forward pass.
But it is quite easy to see that both of these tasks do not require the same amount of “thinking” or (more down to earth) amount of computation to be solved. Indeed one is very easy (just do addition) while the other one requires to compute several expensive operation (a lot of euclidian division)
This can mean two things:
- either LLM are always over thinking to answer every question. (Upper bound)
- or they are just under thinking and cannot show real advance thinking (Lower bound)
Obviously I believe in the second point. I thought my demonstration would convince everybody at this point.
Chain of tough
But then one of my colleagues hit me (very hard) with the truth. This argument makes almost non sense if I don’t consider the use of chain of thought.
Indeed with a chain of thought the model could lengthen its computation budget for the problem and scale it to whatever computation it needs to solve its task by just allowing himself to produce more tokens.
Basically what the model would do with a chain of thought is to first come up with a “plan” or a set of instructions that it will later follow. In the example of the prime number it could first write the algorithm to compute a new prime number and follow this algorithm “by speaking out loud” about each step of the algorithm. At the end it will just output the 10 prime numbers. The total tokens produced by the model and therefore the amount of compute will be way more important. The modal has been able to adapt its compute budget to the difficulty of the task.
This is a clear counter argument to my example. Thinking about LLM capability without allowing them to leverage trick like Chain of Though is a mistake and show me that I probably had a shallow understanding and what we can do nowaday with “just next token prediction”
Reasoning via language only is inefficient
Though, there is one thing that I don’t like: it is losing a debate. So I had to force myself into expressing my intuition that next token prediction (only) is just a phase into the AI journey to real intelligence.
Yes Chain of Tought is a form of reasoning, no it is not similar to what humans are doing: it is a computationally inefficient reasoning that hack LLM a.k.a statistical auto regressive model into “reasoning” or planning ahead. The main point of my argument is that reasoning via words only is slow as hell. This seems like a totally wrong assumption at first read, indeed most of us (especially scientist and literary person) might believe that language formulation and inner dialogue is the essential part of human intelligence.
But it is not (disclaimer I am not a scientist working on this field though so don’t take it as granted) for several reasons:
-
Animals obviously show some strong reasoning ability to who is kind enough to see it. If we are amazed by babyAGI we should be amazed by the intelligence that certain animals can demonstrate. And animals don’t talk (or at least not like we do) and therefore don’t have inner dialogue (with spoken language). This first shows that a form of reasoning and planning can exist independently from language, but it does not prove that language is more or less inefficient.
-
Humans as well can show some reasoning ability without talking nor using inner speech. I am only in my head so I can give some examples where I don’t (necessarily) use my inner speech to think and still plan ahead: coding, playing card games, cooking, tidying up my pace, solving puzzles, playing football
Okay, seems like it is possible to reason without inner speech. Why would it be faster ?
Let’s take a look at this video where Lionel Messi uses the referee as an obstacle to dribble it’s opponent.
It is quite easy to see that messi could not have used any inner speech reasoning to achieve this move:
- This situation is uncommon enough that we can assume this is the first time he encountered it. So he could not have planned it before and he could not have just executed it without thinking ahead.
- It is not luck or a random move. Messi is probably the best football player ever and he is known to pull out some trick that nobody has seen before: he is a very intelligent player
- Last but not least, he took less than half a second to decided
Between the time he received the ball turned his back, saw his opponent in front of him, decided to dribble rather than doing a pass, saw the referee, saw that he could trick the defender into bumping into the referee, decide that is was worth it, execute it, only half a second had pass. How many words can you pronounce internally during half a second ? max 10 if you are a fast thinker ? Do you think that it is enough to plan ahead for such a brilliant move ?
Obviously no, this IMO proves that we humans can reason efficiently without an inner speech. But more importantly this shows how inefficient it is to use natural language to reason (in this case).
Yes humans excel at reasoning when they are able to leverage inner or outer speech but this is only a high level reasoning, most of the small reasoning steps are non verbal. Large Language model may be able to reason with tools like chain of thought, but it is inefficient reasoning.
Language is a bottleneck to reasoning
Language exists because humans need to communicate with each other. Written language exists as a way to put on paper the oral language: speech. This means that all of our language is conditioned by our ability to create sound with our vocal cord. If Human were only reasoning via language it would basically mean that our intelligence is more conditioned by the muscle of our mouse rather than by the size of our brain.
Human intelligence is first non verbal. it becomes verbal when we need to express it, tell it, write it on paper to not forget about it. But it is essentially non verbal. Reasoning at the words (or token) space is a very slow process that is not suitable for the long term planning that is needed for human intelligence.
Reasoning should happen in its own embedding different from the token space which is different for each problem. List of tokens is too high dimension compared to the dimension required to perform reasoning on a task specific problem.
There is a reason that next token prediction is only working for text and not for pixel or audio, it is a solution that only works on our own abstraction of the world. Language is our tokenization of the world. But it is meant only to be used to communicate between humans, not within humans.
To me this is just like what happened with stable diffusion. Researchers realized that it is super inefficient to perform the generation step in the pixel step but they should rather do it in a smaller dimension embedding space. If the same happens for reasoning we could expect a boost in speed and therefore capacity for the same compute budget.
Somehow I have the feeling that reasoning with COT is basically like if we were reasoning outloud but we would be limited to only speaking in morse, the throughput would be such a bottleneck.
Conclusion
COT is a way to make next token LLM reasons better than they do off the shelf. But it is to me just a (useful) hack of LLM to force emerging property.
LLMs are great powerful tools, but they won’t be the last solution to what everybody expects from a fully intelligent AI system and I am not even speaking about AGI or superhuman intelligence.
Though I have to say it is impressive what we can do with LLM nowaday and Chain of Thought is arguably a breakthrough.